Big-O Notation Explained Without the Math Headache
Big-O tells you how code slows down as data grows. Here's the intuition behind O(1), O(n) and O(n²) — explained with everyday examples, no calculus.
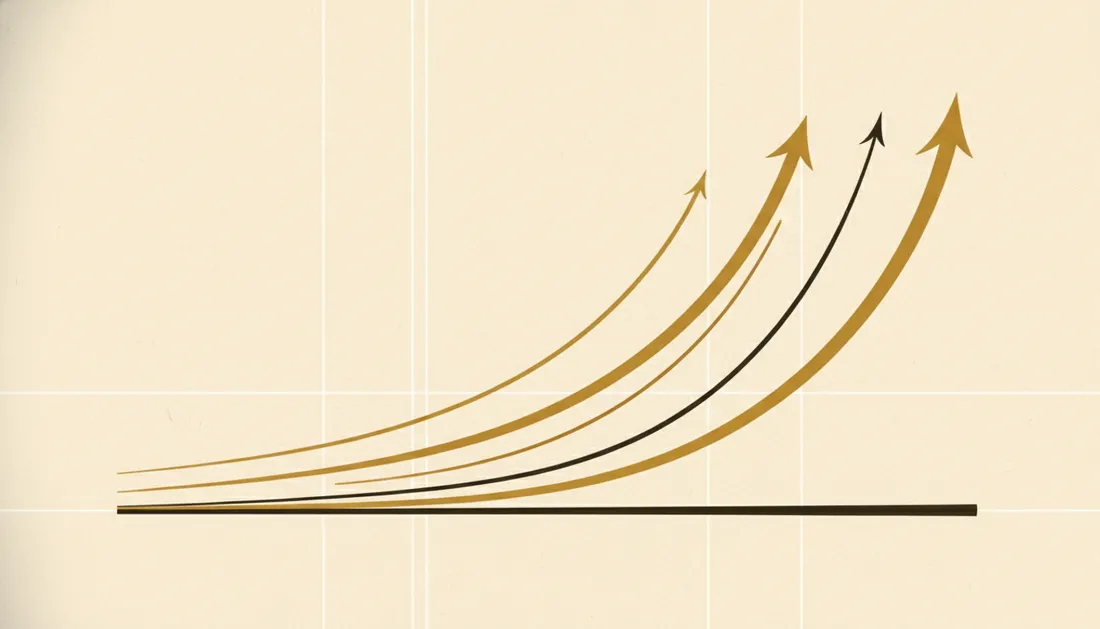
Big-O notation sounds like maths homework, but the idea is simple and genuinely useful: it describes how much slower your code gets as the data grows. You don't need calculus — just a feel for a few common shapes.
The one question Big-O answers
"If I give this code 10× more data, what happens to the time?" That's it. Big-O ignores exact seconds (those depend on your machine) and focuses on the shape of the growth.
The shapes you'll actually meet
- O(1) — constant. Same time no matter the size. Looking up a value by key in a hash map. The dream.
- O(log n) — logarithmic. Doubling the data adds one step. Binary search: find a name in a sorted list by halving it repeatedly.
- O(n) — linear. Twice the data, twice the time. Reading every item once.
- O(n log n). The speed of good sorting algorithms. Slightly worse than linear, totally acceptable.
- O(n²) — quadratic. A loop inside a loop. 10× the data = 100× the time. Fine for small n, dangerous for big n.
An everyday picture
Imagine finding a friend's number in a phone book. Checking every page in order is O(n). Opening the middle, deciding which half, and repeating is O(log n) — which is why it feels so much faster. Comparing every person to every other person ("who shares a birthday?") the naive way is O(n²).
Big-O won't tell you how fast your code is. It tells you how badly it will betray you when the data grows.
Why it matters in real life
Code that's snappy on 100 rows can freeze on 100,000 if it's O(n²). Recognising that nested loop — and reaching for a hash map (O(1) lookups) or a sort (O(n log n)) instead — is one of the highest-value instincts a developer can build. You don't need to compute Big-O formally; you need to smell the quadratic loop and know a faster shape exists.
Key takeaways
- Big-O describes how time grows as data grows, not exact speed.
- Know the ladder: O(1) < O(log n) < O(n) < O(n log n) < O(n²).
- Nested loops are the classic O(n²) trap.
- Hash maps (O(1)) and sorting (O(n log n)) are common rescues.
Frequently asked questions
Why do we ignore constants in Big-O?
Because Big-O describes how cost grows, not its exact value. For large inputs, an O(n) algorithm beats an O(n²) one regardless of constant factors, so we drop the constants to compare shapes.
Is O(1) always faster than O(n)?
For large inputs, effectively yes — O(1) doesn't grow with data. For tiny inputs the difference can be negligible, but Big-O is about behaviour at scale.